PDF?
A Polyglot within a polyglot?
This is part of a series of CTFs for an awesome security company.
The file received was [redacted].pdf
The file is a manual for the NES, or is it a polyglot? It’s called [redacted], which sounds like a huge clue. Let’s see if it is a zip file as well.

Sure enough, [redacted].pdf is also a zip file that contains two more files.
- Mesen.exe -> NES Emulator
- Doc.pdf -> PDF file
I found a small recent article about this in PagedOut:
A guide to ICO/PDF polyglot files
In the article it explains there’s a way to make a file both a valid icon and pdf file. Potentially something similar is going on here. We’ve seen the pdf is also a zip file, what header does it have?
![Hex editor view of the [redacted].pdf header showing NES at the beginning](/static/images/pdf/zip-header-480w.jpeg)
Wait, it’s an NES rom as well? Damn, ok. Let’s load up the ROM in our emulator.
![The [redacted].pdf running in a NES emulator](/static/images/pdf/nes-rom-640w.jpeg)
Yep, it’s a valid ROM image. I pulled out just the NES image from the pdf so it’s only 25kb.
Ok, after playing around in the debugger a bit, it’s clear I need a better view of this statically. Next step is to get this thing loaded in Ghidra successfully.

Not everything is labeled very well, but I can at least see the disassembly.
When I start pressing buttons on my keyboard, some things appear in the little prompt $> on the game.
Here’s the controller mapping:
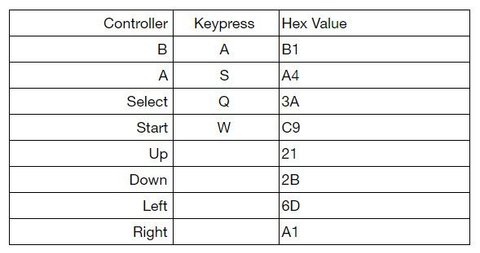
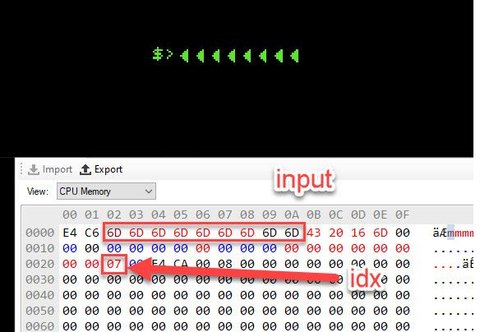
I stared at this for a good moment trying to figure out where the data getting loaded into the Accumulator was going…then I saw it’s a dereference, ugh. There’s some secret data our values are getting xor’d with here:
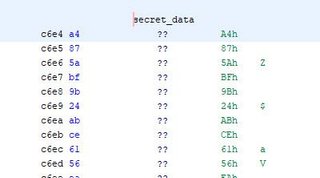
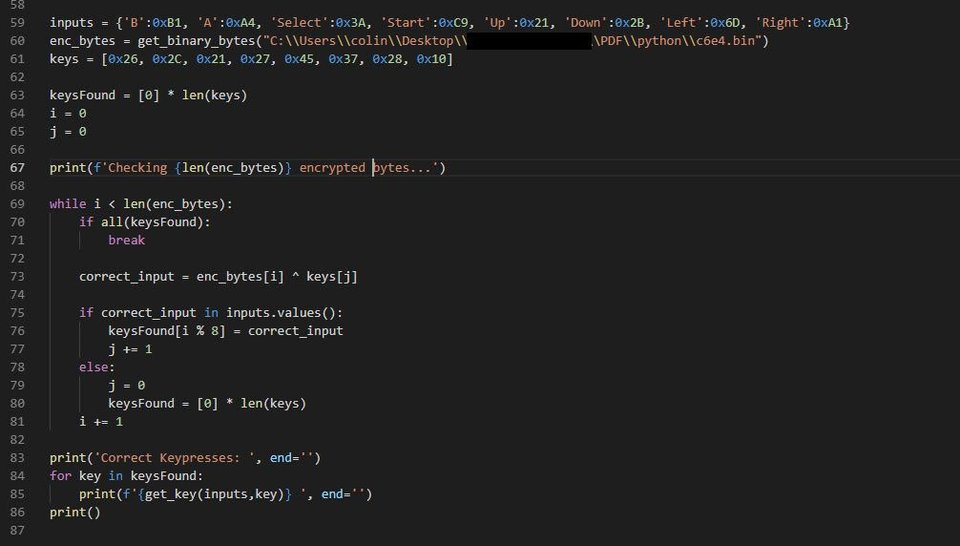
The code goes through the secret data and ^ each key of our input. It puts this newly written data at 0x400.
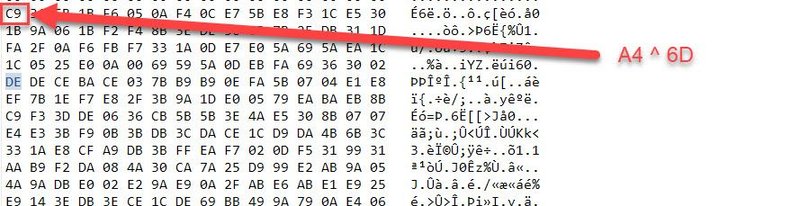
It fills up this buffer just xoring the encrypted bytes at 0xC6E4 with our input looped.
Once that’s done, it scans for the pattern located at: 0xCB48 which is this pattern:[0x26, 0x2C, 0x21, 0x27, 0x45, 0x37, 0x28, 0x10]
It searches 0x400 - 0x7FF for this pattern, if it finds it, we get the flag.
Wrote a python script to search for the result.
All in all, fun challenge. I didn’t realize there were so many possible file types for polyglots, but it’s seemingly endless, specifically because of the PDF specification in that the header can be in any of the first 1024 bytes.